Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124


📉 The Reality Check
On paper, AI monetization looks like a gold mine. The demo works, costs seem manageable, and the Stripe projections look exciting. But then growth starts, and something uncomfortable happens: Margins don’t improve; they shrink.
This is the part almost no guru talks about: the hidden cost curve. At Like2Byte, we’ve analyzed workflows that look affordable at 10 users but collapse at 1,000—not because demand disappeared, but because Total Cost of Ownership (TCO) quietly overtook revenue.
Most teams focus on a single line item: API credits. That focus creates a dangerous blind spot. In production, AI costs are cumulative and volatile.
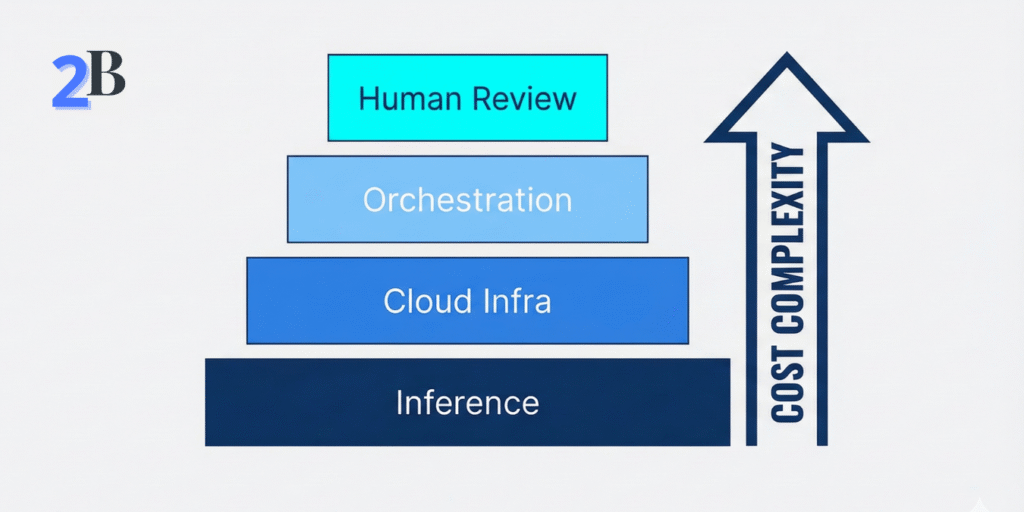
In traditional SaaS, the cost of serving a user is predictable: a few database queries and some server time. In AI, inference costs scale with behavior, not seats. This is what we call the “Inference Tax,” and it is highly volatile.
The cost of a single request is determined by the Context Window. If a user submits a 500-word document, it costs pennies. If that same user, under the same flat-fee plan, starts uploading 50-page PDFs for the AI to analyze, your cost per request can spike by 1,000% instantly. You are paying for every token the model “reads” before it even starts “thinking.”
Furthermore, “Behavioral” cost includes Output Density. A user who asks for a “one-sentence summary” is cheap; a user who asks to “rewrite this entire book chapter in 5 different styles” is an architectural liability. This extreme variance is the core reason why traditional SaaS pricing breaks in IA. As noted in the a16z analysis on AI margins, we are moving from zero-marginal-cost software to a new era where infrastructure and unit economics are the main characters.
In a demo, an agent performs a task and it’s beautiful. In production, agents encounter “Transient Failures”—temporary API timeouts or rate limits. If your orchestration layer isn’t built with exponential backoff and strict circuit breakers, you fall into a Retry Storm.
Imagine a workflow where Agent A calls Agent B. Agent B fails. Agent A retries 3 times. But each retry from Agent A triggers the entire sub-workflow of Agent B again. Suddenly, a single $0.10 user request has generated $4.00 in recursive API calls before your monitoring alert even fires. This isn’t a bug; it’s a structural cost of autonomous orchestration that most spreadsheets ignore.
Even if you are using “serverless” LLMs, your workflow isn’t infrastructure-free. To make AI reliable at scale, you need a high-performance Shadow Layer: vector databases (Pinecone, Weaviate) for long-term memory, Redis for semantic caching, and specialized logging (like LangSmith or Helicone) to trace prompts.
At 1,000 users, the cost of storing, indexing, and retrieving these “conversation states” can rival your actual inference bill. Most builders forget that every token processed must often be logged for compliance or debugging. In 2026, Data Residency and Observability are no longer optional—they are a recurring tax on every single prompt your system handles.
The most dangerous lie in AI monetization is that “the model replaces the human.” In reality, the labor shifts from doing the work to governing the output. As your volume grows, so does the statistical certainty of hallucinations.
This creates an invisible human cost: Human-in-the-loop (HITL) verification for high-risk cohorts, manual prompt re-optimization when model providers update their weights (Prompt Drift), and a support load that is 3x heavier than traditional SaaS because users aren’t reporting “bugs”—they are reporting “wrong logic.” If you don’t price this human intervention, your margin will vanish into your payroll as you scale.
This is the most dangerous cost because it doesn’t show up in your cloud dashboard. Humans verify outputs, fix hallucinations, and handle edge-case escalations. What starts as “automation” often turns into “AI-assisted labor.” If this human involvement isn’t explicitly priced, it will eat your margins alive as you grow.
⚠️ Scaling Paradox: The Cost Explosion
| Cost Layer | When it Spikes | Surprise Factor |
|---|---|---|
| Inference | Long Context | Scales with input messiness |
| Infra | Reliability Steps | Logging & retries add up |
| Human Labor | 1,000+ Users | Edge cases become frequent |
The most common lie in AI monetization is that the model replaces the human. In reality, the model often shifts the human labor from “Doing” to “Governing.” At scale, this shift becomes your largest line item. Here is what you are actually paying for:
According to research by Andreessen Horowitz (a16z), AI startups are facing structurally higher Cost of Goods Sold (COGS) than traditional software. This is why choosing the right monetization model is critical before you push the scale button.
Before you push your workflow to 1,000+ users, run your numbers through this “Stress Test.” If you can’t answer these, your margins are a guess, not a strategy:
Run the “Margin Stress Test”:
Edge cases multiply exponentially. At 10 users, you can patch prompt bugs or fix hallucinations manually for free. At 1,000 users, those “small fixes” require a dedicated support team, robust monitoring (Observability), and complex automated guardrails. This turns a lean, low-cost workflow into a high-overhead operation where margins are eaten by operational complexity.
Token Arbitrage occurs when a power user’s consumption cost exceeds their subscription revenue. Because AI costs are variable based on input length and model reasoning (tokens), a single user running recursive agents on a flat-fee plan can cost the company 5x what they pay monthly. Without usage-based caps, your most active users can literally bankrupt your margins.
In 2026, for high-stakes workflows (legal, financial, medical), HITL is a necessity that builders often misprice as a hidden cost. The mistake is treating human review as a temporary “fix” rather than a permanent line item. If your workflow requires human verification, that labor cost must be baked into your unit economics from day one.
Prompt Drift happens when model providers (OpenAI, Anthropic, etc.) update their underlying weights, causing your previously optimized prompts to behave differently. This leads to higher failure rates and forces expensive engineering hours into re-optimizing and testing core workflows—a recurring maintenance cost that many forget to model in their TCO.
Reliability and Observability. Maintaining “five nines” (99.999%) uptime in AI isn’t just about the API; it’s about the logging, vector database storage, and the orchestration layers that handle timeouts and retries. Following industry reliability standards adds layers of cloud billing that most MVPs completely ignore.
Yes. Strategies like Semantic Caching (storing previous answers to avoid new API calls) and Model Distillation (using a cheaper model for validation and a premium one only for final output) can significantly improve margins. As detailed in Databricks’ engineering guides, performance tuning is often more impactful for profit than simply raising prices.
In 2026, the winners won’t be the teams with the flashiest demos or the cheapest AI. They will be the builders who model cost honestly, design for failure, and treat AI as infrastructure — not magic.
If growth makes you nervous instead of confident, that feeling isn’t fear. It’s a signal. Your unit economics are already under pressure — they just haven’t surfaced yet.
Profitable AI businesses don’t scale first and fix later. They fix cost visibility, governance, and boundaries before scale makes the problems impossible to ignore.