Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124


Quick Answer (2026): If your AI touches PHI/PII/NPI, “cloud convenience” quickly turns into governance cost. Private local AI keeps sensitive data inside your controls and simplifies evidence for HIPAA and GLBA Safeguards.
Educational only. Validate requirements with your compliance/legal team.
Here’s the uncomfortable reality: most “AI data leaks” aren’t Hollywood hacks — they’re governance failures: unclear data flows, weak vendor boundaries, and missing audit evidence once sensitive documents touch third-party processors.
That’s why ROI is really about prevention: IBM’s 2025 breach research (as summarized by ITPro) reports the average U.S. breach cost rose to $10.22M, and incidents tied to shadow AI added ~$670k on average — which reframes “private local AI” as a way to reduce external processors, tighten data boundaries, and keep audit proof in-house (see ITPro summary and IBM’s 2025 Cost of a Data Breach release + report download link).
This guide is written for a procurement manager or compliance lead with limited time. It answers four questions that actually matter:
Cloud AI can be compliant — but it makes governance expensive. In regulated workflows (real estate + insurance), the real cost isn’t “model quality.” It’s proving who processed what data, where, under which controls, and with which subcontractors.
If your AI touches PHI or NPI, you’re operating inside strict expectations for safeguards, auditability, and vendor oversight. Start with the primary sources: HHS HIPAA Security Rule and the FTC GLBA Safeguards Rule. If you serve EU clients, cloud processing also intersects GDPR guidance (EDPB) and, in many AI use cases, the EU AI Act.
Cloud setups typically fail procurement/compliance reviews for one reason: missing evidence. It’s not enough to say “the vendor is secure.” You need defensible answers for audits, renewals, and incident response.
A practical governance baseline for AI is the NIST AI Risk Management Framework (AI RMF) — useful because it forces the conversation away from “features” and into controls, measurement, and accountability.
Most cloud incidents are not “the model got hacked.” They are governance failures: data moves through more systems than the firm can track, across regions the firm didn’t approve, under policies the firm can’t enforce quickly.
| Governance Risk | What compliance/procurement asks | What “good” looks like |
|---|---|---|
| Auditability gaps | Show evidence: logs, retention, access, incident history | Per-request logs + enforceable retention/deletion + least-privilege access |
| Residency & cross-border exposure | Where is data processed/stored/backed up? | Explicit residency controls + documented data map + approved regions only |
| Vendor lock-in & policy drift | Can we exit in 90 days? What changes without consent? | Portable architecture + clear DPAs + contractual change control |
Bottom line: cloud AI can be viable, but in sensitive workflows it often becomes a governance tax. That’s why many firms move the highest-risk data flows to private local AI first — to reduce processor count, tighten residency, and make audits defensible.
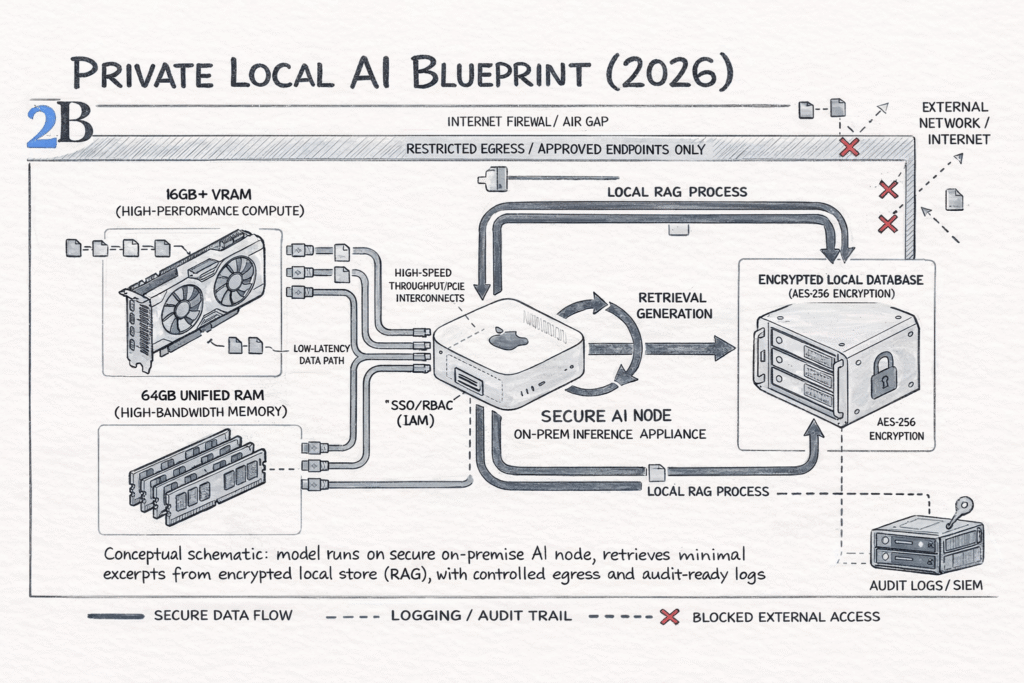
Private local AI is a governance decision first, a model decision second. For real estate and insurance, the job is to keep regulated client data (PII, financial records, underwriting context) inside your controlled environment while still enabling high-leverage AI workflows.
Use these as your baseline references for risk, controls, and evidence: HIPAA Security Rule, GLBA Safeguards Rule (FTC), NIST AI Risk Management Framework (AI RMF 1.0), and (if you serve EU clients or process EU resident data) the EU AI Act.
Hardware note (2026): for many teams, a “secure inference box” can start with compact on-prem hardware like a Mac Mini M4 (or equivalent unified-memory architectures from 2025/26) and scale up to workstation-class GPUs when workloads justify it — the boundary and audit controls matter more than the brand of the box.
Procurement and compliance should set a simple policy: what data can leave, what cannot, and what must produce an auditable trail. In practice, “private local” usually means:
You don’t need a “platform.” You need a contained system with four layers: (1) model serving, (2) data layer, (3) access control, (4) logging/monitoring. Security teams can map controls to standards and common failure modes (e.g., OWASP Top 10 for LLM Applications).
| Layer | What “good” looks like (2026) | Evidence procurement/compliance wants |
|---|---|---|
| Model serving | Private endpoint, network segmentation, rate limits, policy-based prompts/guardrails | Access policy, network diagram, change control |
| Data layer | Encrypted storage, retention rules, scoped indexes (only what’s needed) | Data inventory, retention schedule, encryption posture |
| IAM | SSO/RBAC, least privilege, separation of duties (admins vs users) | Role matrix, access reviews, joiner/mover/leaver process |
| Logging | Prompt + retrieval trace + outputs (with redaction), anomaly alerts | Audit logs, incident workflow, sampling reviews |
Think of RAG as “answering with your internal documents” without copying them to a vendor. Your documents stay in your environment, and the model only sees the minimum excerpts required to answer the question.
CEO-level test: “Can we ask questions about 50,000 PDFs (policies, claims, contracts) and prove that the data never left our boundary?” If yes, you have private local AI—not just a model running on a box.
Next: we’ll translate this blueprint into procurement-friendly use cases (underwriting, claims, document workflows) and the ROI model that matters in regulated environments.
Private local AI is not a “tech upgrade.” It’s a risk-control architecture that lets you automate sensitive workflows without exporting client data to third parties. For regulated operations, the ROI is driven by auditability, data minimization, and operational throughput—not token pricing.
Governance lens (what procurement/compliance should care about): align the program to recognized controls such as NIST AI RMF and common GenAI security failure modes cataloged by OWASP Top 10 for LLM Apps. For insurance-specific privacy expectations, map to NAIC privacy/security model guidance where applicable: NAIC – Data Privacy & Insurance.
The fastest “win” is turning unstructured documents into structured decisions inside your controlled environment. Typical workloads: intake triage, clause extraction, missing-fields detection, routing, and consistency checks—paired with logging and role-based access.
Local AI makes sense when the “cost of being wrong” is governance-heavy: underwriting/risk classification, eligibility checks, escalation rules, and compliance documentation. If your operation is GLBA-covered, the Safeguards Rule expectations are part of the baseline control conversation (see FTC updates on Safeguards Rule requirements: FTC guidance).
A practical middle ground: keep the model local for summaries, next-step recommendations, and draft responses that reference internal documents—but never send raw client context to external APIs. This supports speed and consistency while keeping custody and retention rules under your control.
Use case (executive version): “The 48-Hour Underwriter.”
Instead of distributing files to a triage team, a local pipeline ingests a batch of policy/claim PDFs, extracts required fields, flags missing evidence, and escalates anomalies for review. The business outcome is faster cycle time with audit-ready logs—and no offsite processing of PII/IP.
If you want one decision rule: prioritize private local AI where PII/IP is central, approvals stall on vendor risk, and you need provable audit trails (not just “the provider said it’s compliant”).
For real estate and insurance firms, ROI isn’t “tokens vs hardware.” The real ROI is permission to automate sensitive workflows without exporting client data—plus auditability and predictable operations. When compliance or contractual risk blocks external processing, cloud pricing becomes irrelevant because that option is effectively not available.
This section gives you a decision-grade ROI lens: where the pain lives, what the local/hybrid architecture solves, and the practical conditions where payback typically shows up within a 24–36 month infrastructure cycle (a more realistic horizon for AI hardware refresh in 2026).
Educational note: The examples below use explicit assumptions to illustrate how to think. Results vary by data sensitivity, regulatory scope, workload mix, and implementation quality.
Instead of a fragile token spreadsheet, model payback with three buckets over a 24–36 month window:
| Bucket | What you measure | Why it matters | Inputs you can actually collect |
|---|---|---|---|
| Ops savings | minutes saved per case × volume | turns automation into a measurable throughput gain | case volume, staff time per case, rework rate |
| Approval speed | time-to-approve AI workflows | reduces “blocked” automation and shadow usage | vendor review time, legal cycles, blocked requests |
| Risk reduction | reduced exposure surface | limits third-party processing and unclear retention | data classification, DLP alerts, audit findings |
Payback happens when (Ops savings + Approval speed value + Risk reduction value) consistently exceeds your local stack cost (hardware amortization + ops). If you can’t quantify risk in dollars, quantify it in policy constraints: “is cloud processing allowed for this data class?” If the answer is “no,” the ROI argument becomes operational: local is how you ship the capability at all.
Example scenario (replace the placeholders with your numbers):
If your routine share is high and approval friction is real, you often see payback through cycle-time reduction (faster decisions), lower rework (fewer missing fields/incorrect routing), and fewer blocked deployments. The model doesn’t require heroic assumptions—just operational baselines you can measure in a week.
Practical “payback heuristic”: local AI is a strong candidate when routine work is > 70%, sensitive data is involved (PII/IP), and governance currently forces teams into delays, exceptions, or shadow tools. In that case, local isn’t a cost project—it’s a delivery constraint remover.
This audit gives procurement and compliance a credible starting point to scope: (1) what must run locally, (2) what can stay in cloud, and (3) how quickly a hybrid model can unlock automation without expanding third-party exposure.
Private local AI is the default for regulated client workflows. But cloud still wins in specific, defensible cases. The decision is not “cloud vs local.” It’s which data classes are allowed to leave your boundary, and which workloads justify external elasticity.
| Choose cloud when… | Choose local/hybrid when… | What procurement/compliance should verify |
|---|---|---|
| The data is non-sensitive (public or fully anonymized) and workload is bursty | The workflow touches PII/IP (claims, underwriting, contracts, client comms) or has “no external processing” constraints | Data classification, retention/deletion terms, audit logs, and where processing occurs (region/subprocessors) |
| You need temporary scale (short projects, pilots, seasonal spikes) | You need predictable p95 latency, offline reliability, or internal-only access | SLA boundaries, incident response commitments, and evidence you can produce for auditors |
| You’re experimenting with new capabilities before committing infrastructure | The workload is high-volume and routine (extraction, checks, summaries, routing) with steady demand | Vendor lock-in risk (portability), contract exit clauses, and model/data usage policies |
In practice, the clean strategy for real estate and insurance is a hybrid boundary: keep sensitive workflows local by design, and use cloud only for non-sensitive tasks or short-lived spikes. This reduces vendor exposure without blocking innovation.
For regulated firms, private local AI isn’t “more secure AI.” It’s the architecture that makes automation approvable, auditable, and operationally predictable when client data is involved. That is the core business case: you stop leaking sensitive workflows into third-party systems while still benefiting from AI.
Your next step is simple: classify your workflows by data sensitivity, decide what is allowed to leave your boundary, and implement a hybrid model where local handles the regulated core and cloud remains optional for low-risk work. That’s how real estate and insurance teams move faster without expanding compliance exposure.