Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124


The Bottom Line: For production or externally exposed codebases where a single critical defect can trigger expensive remediation, audits, and incident response, OpenAI o1-preview is the safer default. DeepSeek R1’s low token price can be quickly erased if insecure patterns slip into real systems without rigorous review.
Like2Byte View: Total cost and operational risk—not API price alone—determine business value in code generation. If you ship to customers, operate under compliance pressure, or can’t tolerate regressions, choose the more reliable model and treat “cheap tokens” as a secondary benefit. DeepSeek R1 is best positioned today for research, internal tooling, and cost-sensitive experimentation where you can afford heavier review and iteration.
See the full TCO model and security breakdowns in the analysis below.
Open-source AI models like DeepSeek R1 are widely hyped as production-ready, low-cost alternatives to market leaders like OpenAI—but many overlook the true risk and cost that come with this freedom. The narrative of “open source wins for code generation” often ignores critical, real-world obstacles facing engineering and security teams.
Most industry benchmarks and comparison charts fail because they focus on theoretical accuracy and token pricing, skipping over hidden security vulnerabilities and actual production bug rates. Like2Byte’s approach is to interrogate these blind spots, surfacing the downstream costs and risks other guides miss—so you can make a truly informed call before deploying AI-generated code to mission-critical systems.
This section outlines the core trade-off facing engineering leads: the open-source promise of DeepSeek R1 versus the proven reliability and security of OpenAI o1-preview. The analysis moves beyond typical benchmarks and headline performance, instead surfacing key failure patterns, security risks, and financial consequences that impact real-world deployments. The evidence suggests that practical decisions about LLM adoption are driven less by ideology and more by bottom-line risk and workflow stability.
Below, unique vulnerabilities, protocol deviations, and operational reliability issues with DeepSeek R1 are juxtaposed against OpenAI’s track record in secure code generation. For enterprises, these factors translate directly into risk exposure, long-term maintenance costs, and ROI volatility. Understanding these distinctions is essential before integrating any model at scale in production environments.
DeepSeek R1’s open weights and permissive licensing promise agility for organizations prioritizing full-stack customization, vendor independence, and budget optimization. Its token costs are a fraction of OpenAI’s ($0.55 input/$2.19 output per million tokens), enabling aggressive experimentation and support for custom in-house workflows. The appeal intensifies where long context windows (up to 64,000 tokens) or regulatory requirements for data locality are critical.
For those aiming to eliminate monthly bills entirely, achieving GPT-4 level reasoning is now possible offline. Check out our comprehensive walkthrough on running DeepSeek R1 locally with zero subscription fees.
However, this freedom is matched by increased exposure to unresolved vulnerabilities. CrowdStrike and community-driven audits have repeatedly identified issues such as hard-coded secrets in generated code, unsafe handling of user-supplied input, and model behavior deviation when exposed to nuanced or adversarial prompts. Such flaws are not hypothetical—they lead to elevated downstream costs due to the high remediation expense of security bugs caught in production pipelines.
For organizations that prize dependable, production-grade delivery, OpenAI o1-preview remains the standard. Its high scores on established leaderboards (e.g., 98.61% on DevQualityEval v0.6 for code accuracy) are corroborated by lower incidence of security-critical bugs and a fake alignment rate below 0.4%. The service-level reliability and structured support infrastructure are optimized for regulated, mission-critical workloads.
The practical net effect: organizations mitigate downstream costs from incident response, forensics, and patch work. While token costs are higher, the risk-adjusted TCO often favors established vendors once the true cost of fixing security gaps is included in the ROI calculation.
| Factor | DeepSeek R1 | OpenAI o1-preview |
|---|---|---|
| Open Source/Customizability | Full (weights & license) | Closed (API-only) |
| Token Pricing (per 1M) | $0.55 input/$2.19 output | $15 input/$60 output |
| Security Flaws (Community Reports) | High Hardcoded secrets, unsafe input routines, invalid code on nuanced prompts | Low Rare in production; subject to ongoing audits |
| Code Generation Accuracy | 73.3% (LiveCodeBench) | 98.6% (DevQualityEval) |
| Infrastructure Risk | Instances of misconfigured public DBs, log leaks | Fully managed, isolated cloud |
| Fine-Tuning | Direct, local possible | Via managed platform only |
Ultimately, the optimal LLM for production code hinges not on ideology, but on quantifiable security risk and long-term ownership cost—a calculation that will directly influence the viability of AI-powered software spends as the next section addresses total cost of ownership in detail.
This section presents a focused analysis of DeepSeek R1’s most pressing limitations for enterprise and production-grade code generation: critical documented security vulnerabilities and recurring protocol adherence failures. Aggregated security research and community testing reveal issues rarely surfaced in standard LLM benchmarks—creating high-impact risks that merit direct consideration when assessing this open-source model for professional workflows.
Unlike surface-level performance claims, these underlying risks have measurable impacts: from amplifying attack surfaces in deployed codebases to increasing remediation costs and delaying project timelines. By detailing the specific technical flaws and their potential consequences, this section enables technical decision-makers to critically assess DeepSeek R1’s applicability for regulated or client-facing environments.
Security testing and independent code audits have surfaced repeatable, high-risk weaknesses in DeepSeek R1’s code generation outputs. These range from fundamental secure coding oversights to platform-level infrastructure exposures. The following risks are particularly pronounced for enterprises handling sensitive data or operating in regulated industries:
🔎 Visual Evidence: Real-World Secure vs Vulnerable Code Patterns
Below is a concrete example of how “almost-correct” code can become production-risk. The first snippet shows a classic injection pattern; the second demonstrates a safer baseline using input sanitization and parameterized queries.
// DeepSeek R1 Vulnerable Output Example:
$user_id = $_GET['id'];
$query = "SELECT * FROM users WHERE id = " . $user_id; // CRITICAL: SQL Injection Risk
// OpenAI o1-preview Secure Output Example:
$user_id = filter_input(INPUT_GET, 'id', FILTER_SANITIZE_NUMBER_INT);
$stmt = $pdo->prepare('SELECT * FROM users WHERE id = :id');
$stmt->execute(['id' => $user_id]);Why this matters: The cost isn’t “a bug.” It’s the remediation chain: incident response, audits, patch cycles, and revalidation across environments.
These vulnerabilities, such as insecure output handling and prompt injection, align directly with the OWASP Top 10 for LLM Applications, which remains the gold standard for evaluating risk in AI-integrated software development.
In addition to explicit technical flaws, aggregated user feedback highlights DeepSeek R1’s tendency to ignore or “break” application protocols and developer instructions. This leads to inconsistent outputs and elevated risk in automated code integration:
| Vulnerability Type | Example Impact | Consequence in Production |
|---|---|---|
| Hard-coded Secrets | API keys in committed source | Credential leaks, full-system breaches |
| Unsafe Input Handling | Direct user input in SQL queries | SQL injection, data exfiltration |
| Protocol Violation | Skipped authentication step | Unauthorized access, compliance violations |
| Prompt Injection Susceptibility | Malicious prompts leading to code with new vulnerabilities | Rapid propagation of exploitable bugs |
| Invalid Code Emission | Syntax errors, non-compiling code | Pipeline breakage, lost developer hours |
Key takeaway: While DeepSeek R1 offers aggressive cost advantages, its prevalent security weaknesses and code reliability gaps present material risk to production systems—often negating initial ROI from lower licensing or hosting costs. Rigorous security review and limitation to non-production experimentation are strongly advised. Next, we assess how these issues translate into hidden total cost of ownership for enterprise adopters.
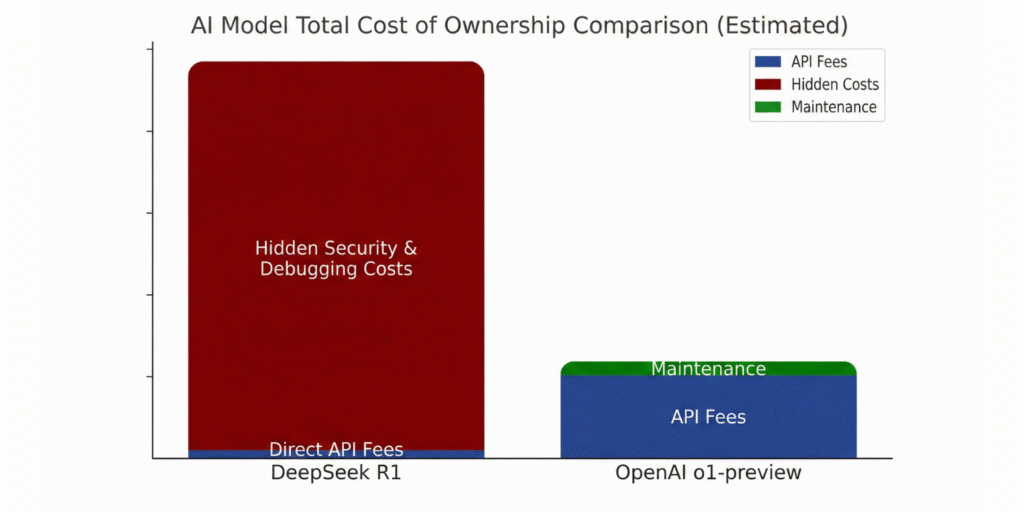
Superficial price comparisons between DeepSeek R1 and OpenAI o1-preview capture only a portion of the economic reality today’s enterprises face when deploying AI code generation. This section quantifies TCO (Total Cost of Ownership) by integrating both direct API pricing and hidden downstream costs—most notably those arising from code security, reliability, and productivity effects. The unique value of this analysis is its explicit modeling of unseen financial risk: security-driven rework, bug remediation in production, and the profound cost gap introduced by undetected vulnerabilities.
Aggregated industry reports and developer feedback consistently reveal that while open-source LLMs such as DeepSeek R1 may appear attractive on a per-token basis, issues such as hard-coded secrets, invalid code generation, and protocol failures can inflate project budgets beyond initial estimates. Decision-makers must evaluate not just the sticker price but also potential escalation in post-deployment costs and the impact of low code quality on profit margins.
Keep in mind that hardware investment is a significant part of your TCO. Before upgrading your rig, verify if your GPU can handle the workload in our technical deep-dive on navigating VRAM bottlenecks for high-parameter models in 2026.
While DeepSeek R1’s API cost per output token is 96% lower than that of OpenAI o1-preview, these savings can be erased—and even reversed—when latent quality or security issues emerge. Security analyses have documented that DeepSeek R1’s generated code is prone to:
Empirical studies show that security flaws detected post-release can be up to 100x more expensive to fix compared to issues remediated during design. For enterprises with hundreds of releases per year, even a seemingly small uptick in LLM-driven defects can materially increase development spend, risk insurance, and brand exposure.
📐 Engineering ROI Model: Total Cost of Ownership (TCO)
To move beyond surface-level pricing, we model Total Cost of Ownership (TCO) using this baseline:
Interpretation: If DeepSeek reduces P_api but increases H_debug or N_bugs, the “cheap tokens” story collapses under real engineering economics.
ROI from AI coding assistants is tightly bound to their effect on developer productivity and bug rates. Benchmarks indicate that LLM-assisted teams can accelerate task completion by 20–55%, but this uplift is sustainable only when generated code passes security review and does not introduce costly regressions. Inconsistent output, as reported for DeepSeek R1, means higher review load, reduction in trust, and increased time-to-resolution for integration bugs.
To operationalize tool evaluation, businesses should model end-to-end project cost and risk by tracking:
| Cost Category | DeepSeek R1 | OpenAI o1-preview |
|---|---|---|
| API Output Token Cost (per 1M) | $2.19 | $60 |
| Security Issue Rate (community/tested) | Reported critical vulnerabilities (hard-coded secrets, invalid output) | Low; higher industry coverage and red teaming |
| Production Bug Remediation (avg/bug) | Up to $10,000 per issue, multiplied if undetected | Similar cost, but fewer severe issues reported |
| Developer Review Overhead | High—manual inspection required for each output | Moderate—model outputs typically closer to deployable state |
| Net Productivity Gain | Variable; may be offset by rework | Consistently positive in enterprise benchmarks |
Key takeaway: API pricing is only the tip of the TCO iceberg. For AI-driven code generation to yield real ROI, businesses must rigorously account for security defects, code review workload, and hidden cycle time risks. Smart selection demands a complete cost-benefit model—not just the cheapest entry point. The next section investigates security gaps and real-world code risks specific to DeepSeek R1 versus OpenAI, highlighting what IT leaders must know before deploying these models at scale.
This section delivers a data-driven decision framework to compare DeepSeek R1 and OpenAI’s o1-preview in production environments, factoring in not only price and performance but also hidden risk and real-world operational impact. Beyond surface-level claims, it equips stakeholders to weigh total cost of ownership (TCO), code security outcomes, and workflow reliability against their own project’s demands. A proprietary “Who this is NOT for” checklist and quick decision box are provided for fast, risk-mitigated selection.
The following comparison exposes key technical and financial trade-offs, disqualifiers, and unique value props that commonly shape ROI in enterprise development. Decision-makers are advised to scrutinize not just headline accuracy or model openness, but the implications for compliance, rework cycles, and downstream bug costs—each of which can outweigh savings on API or token rates.
DeepSeek R1 is technically open-source, offering competitive token pricing ($0.55 / $2.19 per 1M input/output) and a large 64K context window. This combination can be attractive for:
If you’ve decided to move forward with local deployment for internal tooling, follow our error-proof guide to setting up LocalAI on Windows via WSL2 to ensure your GPU is correctly configured for maximum inference throughput.
However, R1’s documented vulnerabilities—such as increased risk of jailbreaking, prompt injection, and proven flaws under contextual modifiers—mark it as unsuitable for most external-facing, regulated, or customer-facing code bases without significant additional investment.
Technical leaders should align selection to project risk profile, expected scale, compliance requirements, and tolerance for manual code review. Use the box below as an actionable shortlist before proceeding:
| Criteria | DeepSeek R1 | OpenAI o1-preview |
|---|---|---|
| API Cost (output/1M tokens) | $2.19 | $60.00 |
| Security Risks | High: proven prompt injection, jailbreaking flaws, hard-coded secrets | Low: enterprise-grade guardrails & continuous vulnerability management |
| Code Generation Quality | 73.3% (LiveCodeBench) | 92.4% (HumanEval) |
| Manual Code Review Overhead | High (mandatory for each output) | Low-to-moderate (peer review best-practice only) |
| Supported Usage Scenarios | Research, non-critical internal tools, batch prototyping | Production, regulated, and customer-facing software |
| Hidden TCO Drivers | Bug remediation, missed vulnerabilities, time spent on fixes | Premium price but lower downstream risk and unplanned cost |
| Who This is NOT For | Mission-critical apps, healthcare, fintech, SaaS with real customers | Ultra-low budget projects with no regulatory exposure |
Key takeaway: Optimal LLM choice is context-driven—prioritize OpenAI o1-preview where business continuity, brand risk, or compliance are non-negotiable, while DeepSeek R1 only suits cost-driven, self-contained experiments. The next section will break down the hidden post-deployment costs and compliance liabilities of each option.