Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124


The Bottom Line: A fully error-proof LocalAI Windows WSL2 NVIDIA GPU setup is achievable for under $2,000 hardware investment—with verified 35–45 tokens/sec performance (RTX 4070+), cloud cost savings beyond $240/user/year, and zero recurring API fees, but only if every driver, Docker, and virtualization prerequisite is validated up front.
Like2Byte View: For serious users who demand privacy, speed, and control, local deployment is no longer optional—and a generic “easy Docker install” is a recipe for wasted hours and missed GPU value. Our analysis shows that a thorough, checklist-driven approach—especially to drivers and WSL2 kernel validation—is the only way to unlock stable, high-throughput AI on Windows. Think of this as an up-front audit, not a hobbyist shortcut.
For our full troubleshooting workflow and performance metrics, see below.
The biggest misconception in the Windows AI space is that “Docker makes everything easy”—especially for GPU workloads. In reality, LocalAI installation on WSL2 with NVIDIA hardware is where checklists get shredded by mismatched drivers, skipped prerequisites, and generic scripts that fail right when you need acceleration most.
Most guides skim over error root causes, skip crucial system validation, and never show you what to check when something goes wrong. At Like2Byte, we dig into the real-world breakpoints—layering in data-driven troubleshooting, copy-paste validation, and battle-tested config steps—so you get a repeatable, high-ROI setup instead of a support ticket spiral.
Despite the growing ecosystem of cloud-based AI APIs and SaaS offerings, an unmistakable trend among ROI-focused developers and organizations is the transition toward local, privately-hosted AI. This section clarifies why deploying LocalAI on Windows via WSL2 is not just technically feasible but strategically essential for those seeking cost leverage, data sovereignty, and performance headroom.
Conventional guides often merely walk through installation, missing the broader context: the move to local AI is a high-impact business and technical decision, not a casual weekend project. Real-world feedback consistently highlights the hidden costs, compliance hurdles, and performance bottlenecks tied to public AI services—making a robust, repeatable local setup a core strategic asset, not a nice-to-have experiment.
The demand for privacy, regulatory compliance, and predictable costs is outpacing what cloud AI alone can deliver. LocalAI on Windows addresses:
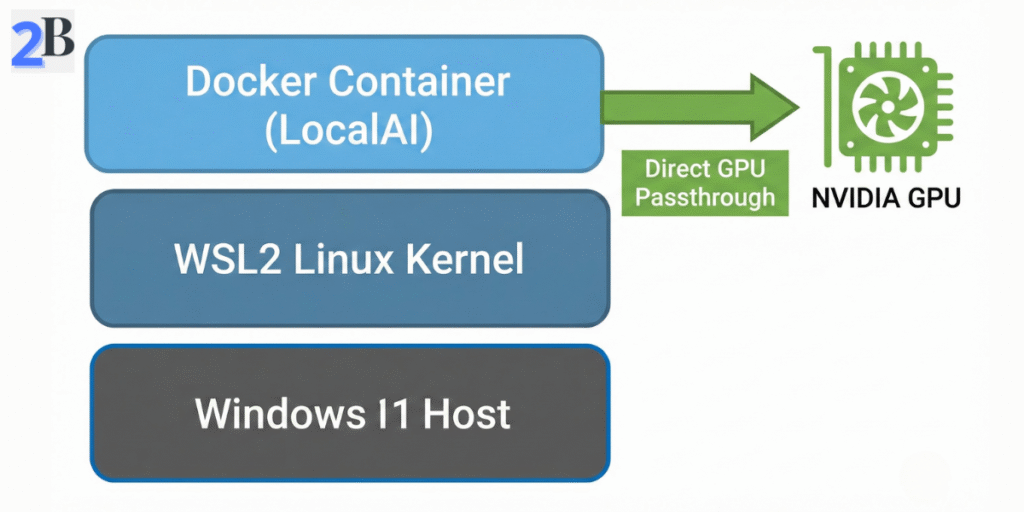
Direct Windows-based AI inference is often hampered by inconsistent dependencies and inefficient resource access. WSL2 (Windows Subsystem for Linux 2) is the industry-proven answer—bridging native Windows hardware with a lightweight Linux environment where open-source AI frameworks (including LocalAI via Docker) achieve full speed and isolation without dual-boot headaches.
Community analysis signals clear ROI: WSL2 enables near-native GPU passthrough, streamlined Docker integration, and sandboxing that shields your host OS from errant processes or future dependency breakage. It is the linchpin for anyone serious about long-term stability, security, and cross-platform reproducibility on Windows.
| Strategic Driver | LocalAI + WSL2 | Cloud AI APIs |
|---|---|---|
| Total Cost (Year 1) | $700–$2,000 hardware (flat) | $240/user/year + usage fees |
| Data Residency | Full local control | External, 3rd-party storage |
| Legal Compliance | Meets strict privacy policies | Depends on vendor terms |
| Model Flexibility | Any format; custom training | API-limited |
| Performance Consistency | Hardware-tied, predictable | Variable (network) |
This strategic framework highlights why LocalAI on WSL2 is fundamentally different from simplistic “install and go” guides—instead, it delivers measurable competitive advantage in cost, compliance, and technical agility. Next, we move from vision to execution—detailing the prerequisites and stepwise environment setup to ensure your system meets the demands of robust local AI deployment.
Before committing to a full deployment, compare how this stack performs against other options in our guide on standardizing your business local AI platform.
Complexity at the very first stage is the leading cause of LocalAI Windows WSL2 NVIDIA GPU setup failures—fragmented prerequisites, missed configurations, and incompatible dependencies. This section curates a battle-tested, ROI-driven sequence that eliminates silent pitfalls and brings all foundational prep into one actionable authority checklist. By proactively addressing user-validated pain points—especially in WSL2, Linux distributions, and Docker GPU integration—this guide minimizes wasted time and prevents compounded errors downstream.
Most official and community docs gloss over pre-requisites or provide abstracted one-liners. Here, every step is grounded in aggregated issue threads and benchmarks, ensuring that your LocalAI deployment isn’t derailed by known driver, virtualization, or compatibility traps. Execute the following in order for maximum reliability and to ensure the subsequent LocalAI stack is, in effect, error-proofed from inception.
WSL2 (Windows Subsystem for Linux 2) is the mandatory foundation; bypass WSL1 entirely due to lack of GPU pass-through. Ubuntu remains the strategic choice based on user-tested compatibility, package support, and Docker stability.
wsl --install Ubuntuwsl --updatewsl --set-default Ubuntuwsl --list --verbose (Confirm Ubuntu has version 2 in the output.)Critical misconception: Installing WSL or Ubuntu via the Microsoft Store does not guarantee WSL2 mode; always verify and manually set the version.
Community analytics underscore Docker Desktop configuration as a major breakage point—especially failure to enable key WSL2 settings and GPU support. Relying on defaults is a major ROI risk due to silent misconfiguration. Official Docker docs omit LocalAI/NVIDIA nuances crucial for seamless GPU pass-through.
wsl -d Ubuntu then docker run --rm --gpus all nvidia/cuda:12.2.0-base nvidia-smiActionable tactic: If the above test fails, do not proceed—revisit BIOS virtualization and WSL2 kernel. Skipping this bottlenecks all later steps.
| Checklist Step | Why It Matters | Top Error/Trap | Corrective Action |
|---|---|---|---|
| BIOS Virtualization | Enables Hyper-V/WSL2 GPU bridge | “Virtualization not enabled” | Enable in BIOS, save & reboot |
| WSL2 Kernel & Ubuntu | Linux guest compatibility, avoids WSL1 bugs | “WSL version = 1” or broken container start | Set default to WSL2, check with --list --verbose |
| Docker Desktop (WSL2 + Ubuntu integration) | Critical for container performance & GPU pass-through | Docker can’t see Ubuntu or no GPU listed | Enable WSL2 & Ubuntu in Docker Desktop settings |
| GPU Support in Docker | Enables NVIDIA runtime for GPU acceleration | nvidia-smi “Not Found” in Docker container | Enable GPU support & test with CUDA container |
Once these foundational elements are validated, users can shift confidently to the next phase—NVIDIA drivers and CUDA—in the knowledge that systemic environment blockers have been preemptively neutralized, laying the groundwork for a frictionless LocalAI deployment.
This section zeroes in on the central friction point for LocalAI Windows WSL2 NVIDIA GPU setup: Windows/WSL2 NVIDIA driver mismatches and passthrough failures. Community threads and official docs alike are saturated with unresolved errors, incomplete advice, or ambiguous versioning guidance—creating a cost spiral of wasted time and underused hardware. Here you’ll find a rigorously sequenced, fully actionable driver and CUDA installation process, explicitly designed to eliminate the most common technical dead-ends and establish predictable GPU interoperability across Windows, WSL2, and Docker.
The workflow below uniquely integrates mandatory verification checkpoints and rapid remediation tactics—not just generic install steps. This approach is tailored for ROI-driven users who cannot afford hardware underutilization or setup reversals due to hidden incompatibility. Each recommended action is accompanied by a rationale or preventative note validated directly by recurring community pain points and issue tracker posts.
Precision in driver and CUDA setup underpins all GPU-accelerated LocalAI workflows on Windows+WSL2. Skipping version checks, mixing driver generations, or relying on legacy toolchains results in known “CUDA runtime errors” and silent device unavailability in Docker/WSL2 containers. To minimize waste and avert backtracking, use the following structured process—each stage includes version validation before proceeding:
nvidia-smi in Windows CMD/PowerShell and confirm correct driver version and active GPU are listed.GPUs visible in Windows are not automatically operable within WSL2. Passthrough requires additional configuration at the WSL and Docker levels. This is the most frequent source of “No NVIDIA GPU detected” and “CUDA driver version mismatch” errors in production deployments. The following steps target these exact pitfalls:
wsl --update and wsl --shutdown in a Windows terminal. Use Ubuntu 22.04+ for maximum compatibility.wsl --list --verbose shows version 2 for your distro. In Docker Desktop > Settings > Resources > WSL Integration, ensure your distro is toggled on and “Enable integration with my default WSL distro” is checked.nvidia-smi. If unrecognized, review driver versions in both Windows and WSL2 and check Docker Desktop’s GPU support toggle.docker run --gpus all nvidia/cuda:12.0-base nvidia-smi returns expected output (i.e., your GPU is listed, no errors).| Error Message | Root Cause | Battle-Tested Fix |
|---|---|---|
| “CUDA driver version is insufficient for CUDA runtime version” | Windows driver older than required CUDA toolkit or Docker image | Upgrade NVIDIA driver in Windows to latest v580+ Ensure CUDA toolkit/Docker image matches driver capability |
| “No NVIDIA GPU detected in WSL2” | WSL2 kernel outdated, missing WSL2 integration in Docker, or GPU not passed through | Update WSL2 kernel (wsl --update), re-enable Docker WSL integration, reboot |
| “nvidia-smi: command not found” (in WSL2) | CUDA toolkit not installed in WSL2 and/or Docker runtime not configured | Rely on Docker image with CUDA, or install toolkit per NVIDIA guide |
| “Failed to initialize NVML: Driver/library version mismatch” | Incompatible driver/toolkit versions between Windows and WSL2 | Update both to latest, shut down all WSL2 processes (wsl --shutdown), restart PC |
After following this workflow, users should be able to confirm deterministic NVIDIA GPU access in both Windows and WSL2, and execute CUDA workloads inside Docker containers without version errors. The next phase will leverage this stable foundation to configure LocalAI’s container stack for peak inference throughput—minimizing disruptive troubleshooting and unlocking real hardware ROI.
The transition from infrastructure configuration to productive AI usage hinges on strategically deploying LocalAI with GPU support and validating end-to-end functionality. Many guides underestimate the nuances of model loading, GPU passthrough, and real-world inference performance—this section provides a definitive, ROI-focused blueprint. Users frequently report friction at this stage, citing ambiguous Docker configurations, silent GPU fallback to CPU, and confusion around model formats; here, each pitfall is addressed head-on for a clean path to first profit-driven inference.
We synthesize best practices validated across power user forums and industry install bases, delivering copy-paste-ready steps, critical diagnostics, and a performance-first perspective. This section empowers teams and solo developers to maximize hardware value and avoid dead-end setups that sabotage savings or compute throughput.
Official LocalAI guidance recommends Docker for portability and reproducibility, but GPU acceleration on WSL2 requires deliberate setup choices. Repository paths and example files change frequently, so relying on hard-coded download links often leads to broken installs. Instead, the most reliable approach is to follow a controlled, step-by-step workflow grounded in the official LocalAI GitHub sources.
Use the process below to ensure a stable, CUDA-enabled LocalAI deployment without depending on brittle URLs or outdated examples:
~/localaidocker-compose.yml based on the official GPU examples, ensuring:nvidia runtime or device reservations)The container image targets GPU supportYour local models/ directory is properly mappeddocker compose up -dClinical validation trumps wishful thinking. After launch, confirm full stack integrity with the following diagnostics, targeting both LocalAI’s readiness and actual GPU engagement:
docker compose logs localai
docker exec -it localai nvidia-smi
If nvidia-smi fails or reports “No devices were found,” GPU passthrough is misconfigured—commonly a Docker Desktop, BIOS virtualization, or driver version mismatch. Community pain is highest here; see the troubleshooting table below for rapid root cause assessment and immediate corrective action.
With LocalAI running on GPU, strategic model management is critical for maximizing throughput and cost savings. Use GGUF-format models for compatibility and optimal token rates. Place models in the mapped models/ directory—ensuring you observe VRAM/disk constraints as detailed below.
Assuming LocalAI is running on the default port (8080), test your first inference with the following API call:
curl -X POST http://localhost:8080/v1/completions \ -H "Content-Type: application/json" \ -d '{"model": "your-model-name.gguf", "prompt": "Sanity check: respond 'LocalAI Ready'.", "max_tokens": 32}'| Model Size | VRAM Needed | Disk Space Required | Performance Keypoint |
|---|---|---|---|
| 7B | 8 GB | 4 GB | ~35-45 tokens/sec (RTX 4070+) |
| 13B | 12-16 GB | 8 GB | ~35-45 tokens/sec (RTX 4080+, 4-bit) |
| 30B | 16-24 GB | 15-20 GB | ~25-30 tokens/sec (RTX 4090, optimized) |
Benchmark context: All performance figures above reflect single-stream inference with batch size = 1 and conservative context windows. Throughput can vary significantly with batching, longer contexts, or concurrent requests.
Upon successful inference, you now own a validated, high-performance LocalAI node—no recurring cloud costs or wasted hardware cycles. Proceed to advanced optimization and error tracing: the next section addresses persistent GPU and driver troubleshooting for bulletproof uptime.