Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124


Quick Answer (2026): I cut inference spend by ~70% by routing 80–90% of requests to a local SLM and using a frontier API only for hard cases.
Cloud AI got cheaper in 2026—yet bills still explode. The culprit isn’t “tokens” alone. It’s premium output tokens, network RTT + jitter, and compliance forcing expensive architectures. This guide shows the routing logic and the updated 2026 math behind that ~70% reduction—without pretending SLMs replace frontier models for everything.
| Baseline | Example | Input ($ / 1M) | Output ($ / 1M) | What you optimize for |
|---|---|---|---|---|
| Commodity cloud (cheap) | DeepSeek V3.2 | $0.28 (cache miss) / $0.028 (cache hit) | $0.42 | Cost is low → SLM wins mainly on latency, privacy, offline, governance |
| Frontier premium | OpenAI GPT-5.2 | $1.75 | $14.00 | Output-heavy workflows → SLM routing can cut spend fast |
| Frontier premium | Claude Opus 4.6 | $5.00 | $25.00 | High accuracy + long outputs → hybrid routing is the lever |
Next: where your cloud bill actually comes from (hidden costs), then the exact routing model + break-even math that makes SLMs pay off.
If your AI bill “mysteriously” doubled, it’s usually not the model. It’s your usage shape (output-heavy prompts), network path (egress + cross-region), and operational overhead (rate limits, retries, batching, logging).
Most providers charge separately for input and output tokens. In real deployments, output tokens are the silent killer: summaries, rewrites, “explanations,” and long-form answers inflate output—and your cost—with zero warning.
Even when token prices look “cheap,” cloud deployments often leak money via data egress, cross-region traffic, and operational plumbing (gateways, load balancers, monitoring, retries).
Local/hybrid inference doesn’t eliminate every cost—but it often removes the network leg (round trip + egress exposure) and makes the remaining costs easier to predict.
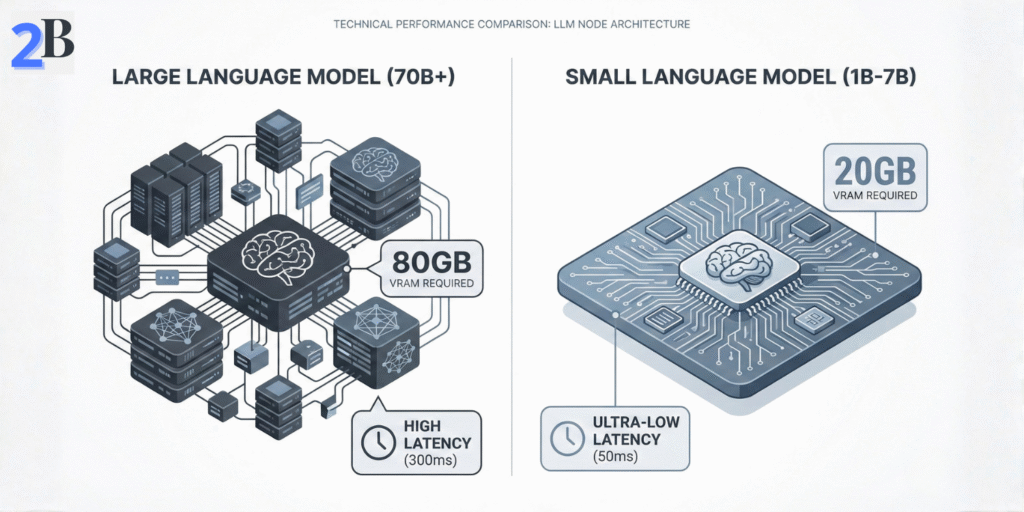
Choosing the right hardware for local inference is a major part of the TCO equation; for instance, the Mac Mini M4 can be a strong local LLM/SLM host thanks to unified memory (especially for smaller models + quantization).
If you track only “average latency” and “$/token,” you will miss the real pain. For business planning, these three metrics predict cost blowups and user complaints:
| Cost Leak | What it looks like in real life | What to measure | What to do |
|---|---|---|---|
| Output bloat | Answers get longer over time (“helpful” prompts) | Output tokens/request | Enforce max output, use structured templates, route short tasks to SLM |
| Context bloat | RAG + chat history grows silently | Input tokens/request | Trim history, compress context, cache stable prompts |
| Network & egress | Cross-region + outbound fees | Egress GB/month + regions | Keep data local, reduce payloads, consider hybrid/local inference |
| Ops tax | Retries, throttling, queueing, logging | Retry rate + throttles + error rate | Batching, backoff tuning, capacity planning, model routing |
Bottom line: cloud LLM bills don’t explode because “AI is expensive.” They explode because output grows, network costs sneak in, and ops overhead compounds. In the next section, we’ll map exactly how SLMs reduce these leak points—without pretending you should abandon cloud models entirely.
SLMs are the “workhorse layer” of enterprise AI in 2026. They handle the majority of repetitive tasks (classification, extraction, templated summaries, routing) at a fraction of the infrastructure footprint—while you reserve frontier models for truly hard reasoning.
In practice, “small” in 2026 means models you can run reliably on modest hardware (edge devices, a single workstation GPU, or a small on-prem box) without needing a cloud GPU cluster. The sweet spot has expanded beyond 1B–7B into ~3B–14B models that are still operationally “small,” but far more capable.
Concrete 2026 examples: Microsoft’s Phi family pushed SLM capability forward (Phi-3 → Phi-4), Google’s open Gemma 2 (9B/27B) targets efficient inference, and Meta’s open-weight line includes Llama 3.1 and newer releases like Llama 4 (Scout/Maverick) for broader capability (with more complex architectures).
You don’t need to memorize techniques—just understand the levers that make SLMs faster and cheaper in production.
For most companies, the goal isn’t “general intelligence.” It’s consistent performance on a narrow set of workflows. That’s where SLMs shine: you tune them on your domain language and templates, then route only the edge cases to frontier models.
If you’re also evaluating “cheap cloud” baselines, we break down that reality in our DeepSeek R1 local hardware and cost guide—where the SLM advantage shifts from pure $/token to latency, data residency, and TCO predictability.
| What changes with SLMs | In plain English | Why a CEO should care |
|---|---|---|
| Smaller footprint | Runs on simpler hardware (local/hybrid) | Lower risk + faster deployment |
| Lower p95/p99 latency | Fewer slow spikes, fewer network dependencies | Better UX + fewer SLA fires |
| Cheaper “routine work” | Offload repetitive tasks from premium APIs | Budget control without losing capability |
| Data stays closer | Less data leaving your environment | Compliance + trust + fewer security headaches |
Next, we’ll turn this into dollars: the routing model, the break-even math that actually holds in 2026, and a simple framework to decide what runs local vs cloud.
This is where the article becomes real: my ~70% reduction didn’t come from “SLMs are cheaper per token.” It came from routing + cutting premium output tokens + removing the network leg for the majority of requests.
On the technical side, inference stacks and optimizations can materially reduce memory footprint and improve throughput (see NVIDIA’s inference optimization overview). On the business side, the ROI equation is simple: how many calls can you safely offload to a local SLM without hurting outcomes?
User Request
│
├─► Policy Gate (PII/IP? regulated?)
│ │
│ ├─► YES → Local SLM (default) + safe logs
│ └─► NO → Go to Intent Score
│
└─► Intent Score (complexity/ambiguity/output-length)
│
├─► Routine (80–90%) → Local SLM
└─► Hard (10–20%) → Frontier API
In 2026, “LLM cost per token” depends on what you’re buying: commodity cloud or frontier premium. Below are published prices you can reference in purchasing discussions.
| Baseline | Example | Input ($ / 1M) | Output ($ / 1M) | What SLM optimizes |
|---|---|---|---|---|
| Commodity cloud (cheap) | DeepSeek V3.2 (deepseek-chat) | $0.28 (cache miss) / $0.028 (cache hit) | $0.42 | Latency, privacy, offline, governance (not always raw $/token) |
| Frontier premium | OpenAI GPT-5.2 | $1.75 | $14.00 | Big savings on output-heavy workloads via routing |
| Frontier premium | Claude Opus 4.6 | $5.00 | $25.00 | Big savings on long outputs + compliance-driven local processing |
Note: Numbers below are illustrative and will vary by pricing, workload, and infrastructure—use them as a decision framework, not a guarantee
Here’s the exact “shape” I used for the model. The point isn’t that every business has 10M requests/month—the point is that routing turns the math in your favor when your workload is large, output-heavy, regulated, or latency-sensitive.
| Assumption | Value | Why it matters |
|---|---|---|
| Requests / month | 10,000,000 | Scale determines whether capex pays back quickly |
| Tokens / request | 500 total | Most teams underestimate tokens; measure it |
| Split (input / output) | 200 / 300 | Output tokens usually dominate cost on premium models |
| Routing split | 85% SLM / 15% API | The main lever that creates savings |
| Local ops cost | $1k–$2.5k/mo (monitoring, updates) | Prevents “local is free” fantasy |
Same workload. Two baselines. This is why some teams see fast ROI—and others should focus on latency/privacy instead of “cost savings.”
| Scenario | Cloud baseline cost (monthly) | After routing (15% API) + local ops | What happens |
|---|---|---|---|
| Frontier premium baseline (GPT-5.2 pricing) | ~$45.5k/mo (2B input, 3B output) | ~$8.3k/mo (~$6.8k API + ~$1.5k ops) | ~80%+ reduction is plausible because you cut premium output tokens hard. |
| Commodity cheap baseline (DeepSeek pricing) | ~$1.8k/mo (same token volume) | ~$1.7k–$2.6k/mo (cheap API + local ops) | Cost savings may be small or negative. Here the SLM “win” is latency, privacy, offline, governance. |
You may be wondering: “If commodity cloud is so cheap, why run local?”
Commodity APIs can be the right answer when data sensitivity is low and latency isn’t mission-critical. Local/hybrid SLMs win when cloud is constrained by data residency, contractual/vendor risk, offline reliability, or p95 latency.
CEO rule: if legal/compliance says “no external processing” (PII/IP), cloud price becomes irrelevant—because that option is effectively blocked.
Next, we’ll go beyond ROI and show where SLMs win even when cloud is cheap: latency, privacy, and strategic control—plus the “who this is not for” section to avoid bad deployments.
In 2026, the SLM case is bigger than $/token. Commodity APIs are cheap—but enterprises still lose money on latency, data exposure, and unpredictable operational risk. This section is the executive checklist: what matters, when SLMs win, and when they don’t.
CEOs don’t buy “fast models.” They buy predictable operations. The real KPI is p95/p99 latency, not average. Local/hybrid SLM routing reduces network RTT and jitter—especially for interactive tools, internal copilots, and customer-facing workflows.
If you handle PII, regulated data, or sensitive IP, the “cloud vs local” choice becomes governance. Local/hybrid inference can reduce external data exposure, simplify audits, and make data residency enforceable by design.
CEO translation: if compliance or customer trust is a growth constraint, SLMs are a way to ship AI without turning your data into a vendor dependency.
Forget legacy examples. In 2026, procurement should evaluate SLMs as a stack: model + runtime + deployment pattern + monitoring. Here’s the practical checklist.
SLMs are not a universal upgrade. If your organization can’t operate infrastructure—or your tasks are genuinely open-ended and high-stakes—frontier APIs may still be the better default.
| If you are… | Do this | Why |
|---|---|---|
| Low volume + non-sensitive + sporadic usage | Cloud API | Capex/ops overhead won’t pay back |
| Regulated data (PII/IP) + audit pressure | Hybrid (local SLM + cloud fallback) | Data exposure becomes a governance risk |
| Interactive UX where p95 latency hurts revenue | Local-first routing | Network jitter and throttling become business problems |
| Complex reasoning across many domains | Frontier-first, then offload only routine tasks | Keep accuracy high, reduce cost with selective routing |
Bottom line: in 2026, the winning pattern isn’t “SLM vs LLM.” It’s routing + governance + predictable latency. That’s how you keep AI useful—and profitable—at scale.
Often yes—but not purely on $/token. SLMs win when you care about predictable p95 latency, data residency, offline reliability, and governance. If your workload is output-heavy on premium frontier APIs (or cloud is constrained by compliance), routing routine tasks to a local SLM can still cut total spend dramatically.
Intent routing is a decision layer that sends routine requests (classification, extraction, templated summaries) to a local SLM, while escalating only ambiguous or high-stakes tasks to a frontier API. The savings come from keeping 80–90% of traffic off premium output tokens and reducing network round-trip latency.
Start with the last 4 weeks of: (1) output tokens vs input tokens, (2) p95 latency (not average), and (3) % of requests that are routine. If output is consistently > 60% and routine work is > 70%, you’re usually a strong candidate for local SLM routing.
If your usage is low-volume, sporadic, non-sensitive, and you don’t need strict latency guarantees, cloud APIs are often simpler and cheaper than operating local infrastructure. SLMs make the most sense when workloads are high-volume, predictable, regulated, or latency-critical.
No. SLMs are best as the default engine for routine tasks and fast responses. Frontier models remain valuable for complex reasoning, ambiguous prompts, and high-stakes outputs. The most reliable 2026 architecture is hybrid: local SLM first, frontier API fallback.